前言
epub.js 是一个强大的库,算是浏览器这块 epub 文件处理的大哥
但是由于项目时间线跨度大(7 年),API 不友好(相对现在的环境来说),再加上只进行了寥寥几次效果不理想的重构,导致这个库的问题非常多,文档非常简陋,类型声明文件更是一塌糊涂
个人在使用中踩了非常非常多的坑,在此记录,方便以后查阅
解析流程
构建 epub 实例
epub.js 许多接口,其中最直接的使用方法为调用其默认导出的函数,传入文件供其解析
1
2
| import Epub from 'epubjs';
const epub = Epub(target, options);
|
这里的 target 可以是多种类型的数据:
二进制:即 ArrayBuffer
BASE64:base64 字符串,使用该类型需要设置 options.encoding = 'base64'
链接:通过 http 协议获取远程文件
需要注意该链接必须以 .epub 结尾,在源码中 determineType 负责解析输入类型:
1
2
3
4
5
6
7
8
| determineType(input) {
if(extension === "epub"){
return INPUT_TYPE.EPUB;
}
}
|
而只有 INPUT_TYPE.EPUB 类型才会通过 http 协议请求:
1
2
3
4
5
6
7
8
9
10
|
else if (type === INPUT_TYPE.EPUB) {
this.archived = true;
this.url = new Url("/", "");
opening = this.request(input, "binary", this.settings.requestCredentials, this.settings.requestHeaders)
.then(this.openEpub.bind(this));
}
|
解包
经过上面的解析,最后会拿到二进制数据,开始解包:
1
2
3
4
5
6
7
| unarchive(input, encoding) {
this.archive = new Archive();
return this.archive.open(input, encoding);
}
|
解压数据后,根据 epub 标准,解析 rootfile(根文件) 的位置,rootfile 中存放了 epub 中所有的信息(xml 格式):
书名、作者、出版社、简介、发布者、制作时间…
目录文件路径(也是 xml)
所有页面、图片资源的路径
具体实现有点 💩 山的味道了,A 调用 B、B 调用 C、C 调用 D,又长又绕…伪代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
const containerXml = await load(CONTAINER_PATH);
const rootfilePath = resolvePath(new Container(containerXml).packagePath);
const rootFileXml = await load(rootfilePath);
const package = new Packging(rootFileXml);
this.spine = ...
this.resource = ...
this.nav = ...
|
看着就几行是吧,实际上的复杂度比这个高非常多…
(预)渲染
到这里 Book 实例构建完成,接着(预)渲染到页面上:
1
2
|
const rendition = epub.renderTo(el, options);
|
options 签名如下(我看完源码修正过的):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| type RenditionOptions = {
width?: string | number;
height?: string | number;
ignoreClass?: string;
manager?: 'continuous' | 'default';
view?: 'iframe' | Object | Function;
flow?: 'paginated' | 'scrolled';
layout?: string;
spread?: 'none' | boolean;
minSpreadWidth?: number;
resizeOnOrientationChange?: boolean;
script?: string;
stylesheet?: string;
infinite?: boolean;
overflow?: string;
snap?: boolean;
defaultDirection?: string;
allowScriptedContent?: boolean;
};
|
这里开始就有不少坑了,我先说下各个属性的作用,一眼就知道的就掠过:
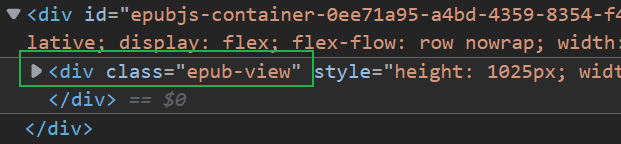
manager:
为 default 时,manager(视图管理器)只会同时挂载一个 view(视图),具体表现如下图所示:
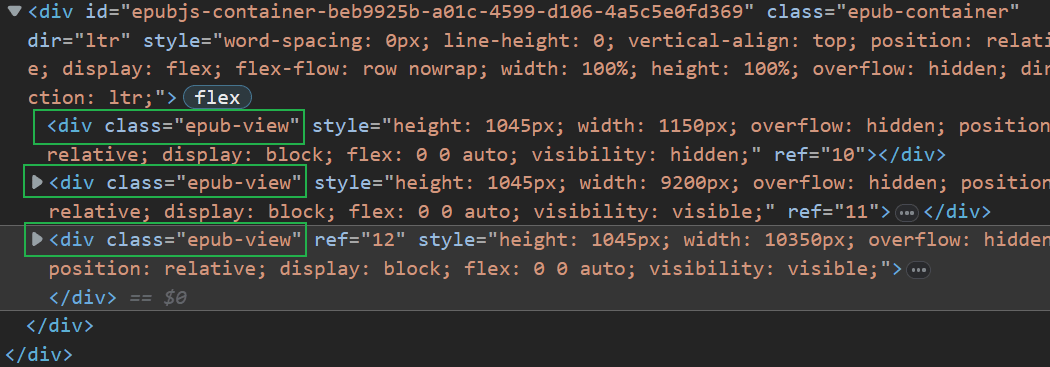
continuous(连续的) 时会预加载前后的页面,同时挂载多个 view,表现如下:
view:
这里只能填 iframe,官方文档写着能传 inline,但实际上代码里没有处理:
1
2
3
4
5
6
7
| if (typeof view == 'string' && view === 'iframe') {
View = IframeView;
} else {
View = view;
}
|
InlineView 其实存在,我不建议使用,问题很多:
flow:
对应两种操作方式,paginated(分页)即传统的左右翻页
scrolled 则是垂直的滚动阅读方式
spread:
是否显示双页,仅在 flow = paginated 时生效
script, stylesheet:
这两项不是代码字符串,它们分别为 link,style 标签的 href 属性,标签会被注入到每个 view 的 head 中,
infinite:
这玩意根本就没实现,无效
snp:
是否支持翻页,仅在 manager = continuous 时生效
有坑,可能会使翻页失效,后面会说
渲染
上面其实只渲染了容器,但是 epub 的内容还未展示到页面上
此时我们需要调用 rendition(渲染器)的 display 方法渲染内容:
1
| await rendition.display(target);
|
target 可以是非常多的东西:
然后我们就能看到书本的内容了
踩坑
toc(目录) 路径问题
当你需要点击目录跳转到对应页面时,会有下面代码:
1
| await rendition.display(toc.href);
|
对于绝大部分图书来说,这样写不会有问题,但是有少部分图书目录的 href 比较怪,此时会导致跳转失败
rendition.display 的实现大致如下:
1
2
3
4
5
6
|
if (this.book.locations.length() && isFloat(target)) {
target = this.book.locations.cfiFromPercentage(parseFloat(target));
}
section = this.book.spine.get(target);
|
重点就在 this.book.spine.get(target),spine 是根据 rootfile 生成的,下面是某个 rootfile 中的 spine:
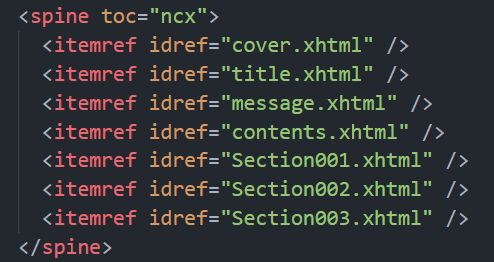
它会根据 idhref,在 rootfile 中的 manifest 找到对应的 href:
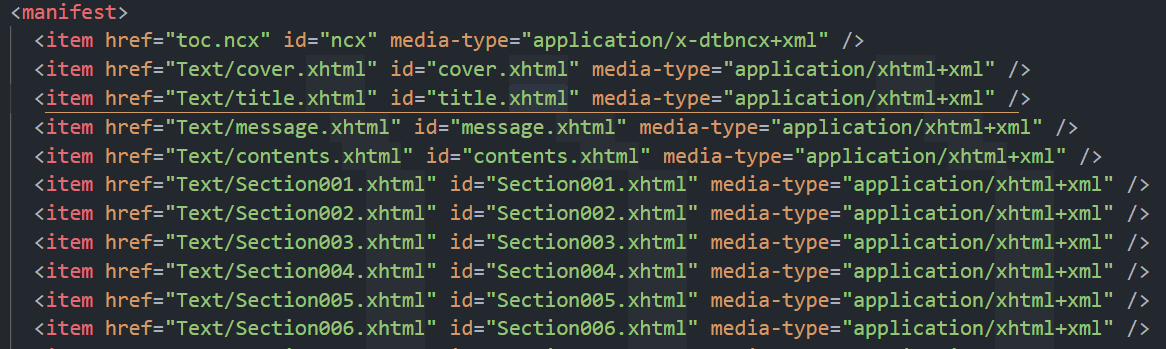
生成这样数据结构的 spine:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| const spine = {
items: [
{ idhref: 'Section001.xhtml', href: 'Text/Section001.xhtml' },
{ idhref: 'Section002.xhtml', href: 'Text/Section002.xhtml' },
{ idhref: 'Section002.xhtml', href: 'Text/Section003.xhtml' },
],
itemsByHref: {
'Text/Section001.xhtml': {
idhref: 'Section001.xhtml',
href: 'Text/Section001.xhtml',
},
'Text/Section002.xhtml': {
idhref: 'Section002.xhtml',
href: 'Text/Section002.xhtml',
},
'Text/Section003.xhtml': {
idhref: 'Section003.xhtml',
href: 'Text/Section003.xhtml',
},
},
};
|
spine.get 会在 itemByHref 中查找其对应的 item,如果找不到就会返回空
此时问题来了,有些书的目录会额外在路径上增加一些乱七八糟的东西,例如下面这一个目录项长这样:
1
2
3
4
5
6
7
| <navPoint id="navPoint-9" playOrder="9">
<navLabel>
<text>②不管何时雪之下雪乃都会贯彻始终</text>
</navLabel>
<content src="Text/Section008.xhtml#heading_id_2" />
</navPoint>
|
此时我们拿 "Text/Section008.xhtml#heading_id_2" 在 spine 中查找 item,自然是找不到的,这会导致无法跳转
解决
自己处理一遍 toc,这是我项目中的代码(简略版):
1
2
3
4
5
6
7
8
9
10
11
| const toc: IToc[] = (await epub.loaded.navigation).toc.map((t) => {
if (t.href.startsWith('/')) t.href = t.href.replace('/', '');
else if (t.href.startsWith('../')) t.href = t.href.replace('../', '');
t.href = t.href.replace(/(?!^)#.*/, '');
return { ...t };
});
|
获得当前页的章节标题
当我们需要获得当前页面的章节标题时,首先得从 rendition 中获得当前的 loc (location 位置),拿 loc.href 去 toc 中找对应的目录:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| const getCurrentProcess = async () => {
await this.ensureLoc();
const loc = this.getLoc();
if (!loc) return null;
return {
value: loc.start.cfi,
ts: Date.now(),
percent: this.epub.locations.percentageFromCfi(loc.start.cfi),
navInfo: this.toc.find(({ href }) => href.startsWith(loc.start.href)),
};
};
|
问题会出现在 toc 的遍历上
假设我们有一本书,它有着这些页面:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| <item
href="Text/cover.xhtml"
id="cover.xhtml"
media-type="application/xhtml+xml"
/>
<item
href="Text/message.xhtml"
id="message.xhtml"
media-type="application/xhtml+xml"
/>
<item
href="Text/contents.xhtml"
id="contents.xhtml"
media-type="application/xhtml+xml"
/>
<item
href="Text/Section001.xhtml"
id="Section001.xhtml"
media-type="application/xhtml+xml"
/>
<item
href="Text/Section002.xhtml"
id="Section002.xhtml"
media-type="application/xhtml+xml"
/>
<item
href="Text/Section003.xhtml"
id="Section003.xhtml"
media-type="application/xhtml+xml"
/>
<item
href="Text/Section007.xhtml"
id="Section007.xhtml"
media-type="application/xhtml+xml"
/>
<item
href="Text/Section008.xhtml"
id="Section008.xhtml"
media-type="application/xhtml+xml"
/>
<item
href="Text/Section004.xhtml"
id="Section004.xhtml"
media-type="application/xhtml+xml"
/>
<item
href="Text/Section005.xhtml"
id="Section005.xhtml"
media-type="application/xhtml+xml"
/>
<item
href="Text/Section006.xhtml"
id="Section006.xhtml"
media-type="application/xhtml+xml"
/>
<item
href="Text/Section009.xhtml"
id="Section009.xhtml"
media-type="application/xhtml+xml"
/>
<item
href="Text/Section010.xhtml"
id="Section010.xhtml"
media-type="application/xhtml+xml"
/>
|
同时它的目录如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| <navPoint id="section001" playOrder="3">
<navLabel>
<text>简介</text
</navLabel>
<content src="Text/Section001.xhtml" />
</navPoint>
<navPoint id="section002" playOrder="4">
<navLabel>
<text>年表</text>
</navLabel>
<content src="Text/Section002.xhtml" />
</navPoint>
<navPoint id="section003" playOrder="5">
<navLabel>
<text>彩页</text>
</navLabel>
<content src="Text/Section003.xhtml" />
</navPoint>
<navPoint id="section005" playOrder="6">
<navLabel>
<text>4/伽蓝之洞 『 』</text>
</navLabel>
<content src="Text/Section005.xhtml" />
</navPoint>
<navPoint id="section009" playOrder="7">
<navLabel>
<text>境界式</text>
</navLabel>
<content src="Text/Section009.xhtml" />
</navPoint>
|
此时,如果我们正处在 "Text/Section006.xhtml",loc 中的 href 就会是 "Text/Section006.xhtml",但是我们观察目录可以得知,toc 里没有对应的目录,那么 navInfo(章节信息)就会为空
解决
大部分的图书,两个目录之间的章节都应该属于前一个目录,所以我们需要额外生成一个哈希表,为没有目录的章节指向它们前面的目录:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
this.flatToc = flatArrayWithKey(target.toc, 'children');
this.flatToc.forEach((item) => {
this.hrefMap[item.href] = item;
});
const spine = this.epub.spine as Spine;
let nextTocIndex = 0;
let prevTocIndex = 0;
const maxTocIndex = this.flatToc.length - 1;
spine.items.forEach((sp) => {
if (sp.href === this.flatToc[nextTocIndex].href) {
prevTocIndex = nextTocIndex;
if (nextTocIndex < maxTocIndex) {
nextTocIndex++;
}
} else if (!this.hrefMap[sp.href]) {
this.hrefMap[sp.href] = this.flatToc[prevTocIndex];
}
});
|
非常简单的双指针算法,此时所有章节都指向了其所属目录
最后修改一下 getCurrentProcess 方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
| const getCurrentProcess = async () => {
await this.ensureLoc();
const loc = this.getLoc();
if (!loc) return null;
return {
value: loc.start.cfi,
ts: Date.now(),
percent: this.epub.locations.percentageFromCfi(loc.start.cfi),
navInfo: Object.entries(this.hrefMap).find(([key]) =>
key.startsWith(loc.start.href)
)?.[1],
};
};
|
注意:这种方法有一定局限性
(极少)部分图书的目录是乱序的,此时该算法为没有目录的章节指向的目录会出现错乱
目前无解,这是文件本身的问题
布局管理器
manager 可以设定布局管理器,有 continuous 和 default 两种
在使用 default 且分页(flow = paginated)时,如果你要在当前章节的第一页翻到上一页(上一章节的最后一页),此时会定位到上一章节的第一页
解决
如果你需要使用分页,那只能使用 continuous 布局,该布局会预载入前后的章节,解决了上面的问题
该布局本身也有坑,它偶尔会在第一次渲染时定位错乱,同时显示两页内容(两页各显示一半),需要调用 rendition.display 重新渲染一次当前位置来解决
无法翻页
频繁的更改窗口尺寸,会导致无法翻页,具体表现如下:
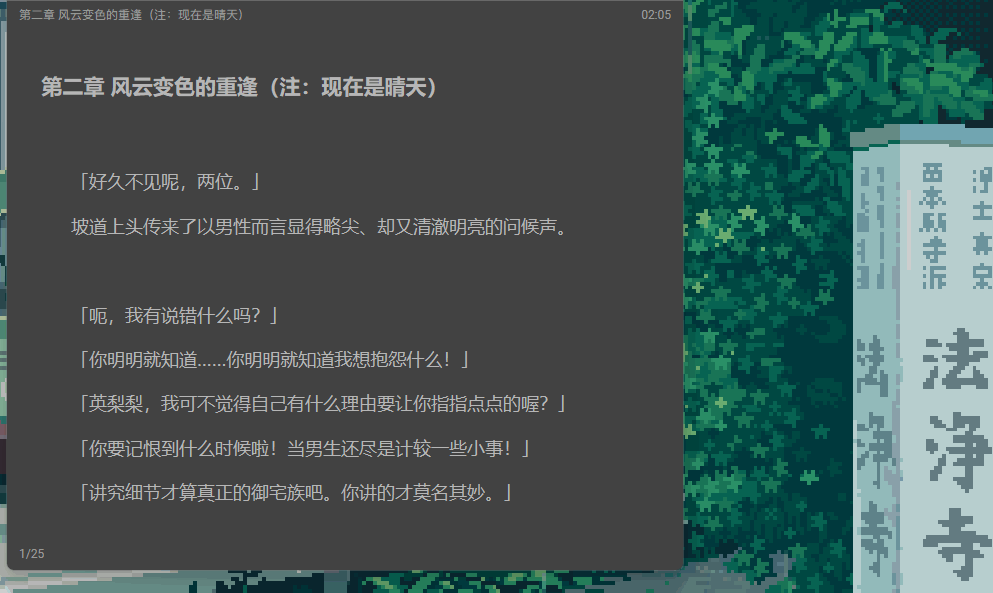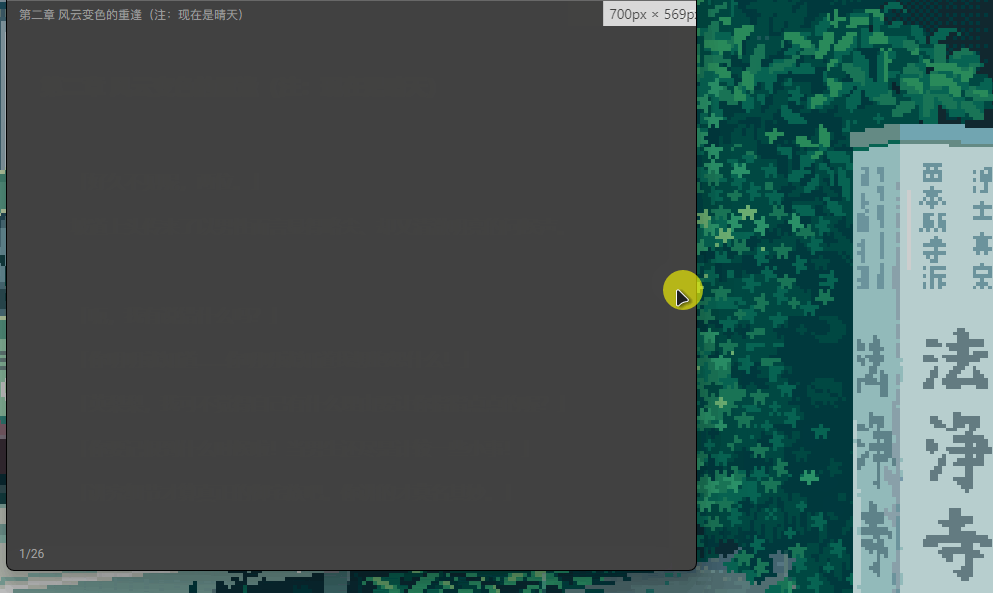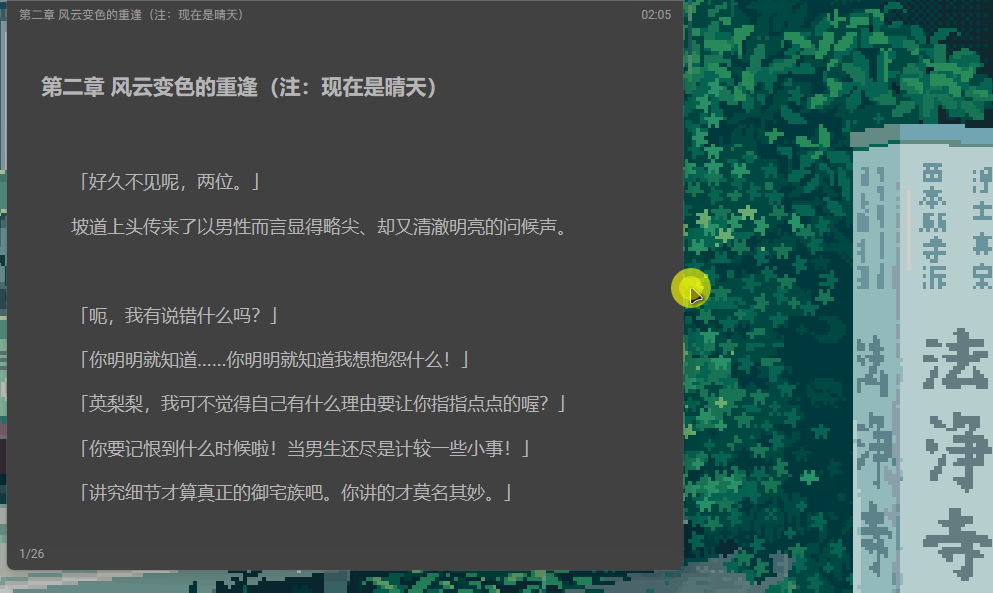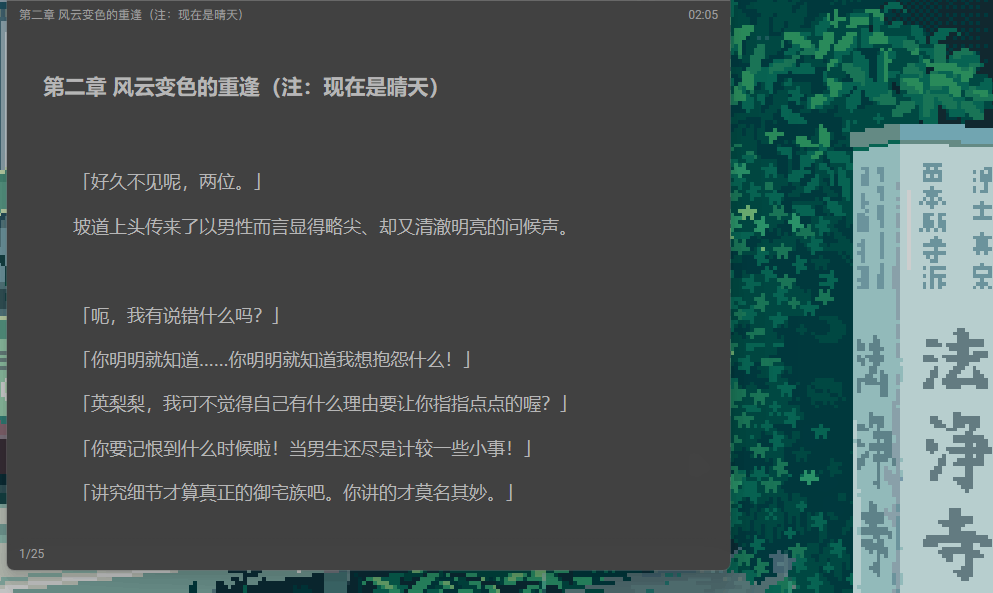
原因有两点:
epubjs 内部使用了 Promise 队列 的方式管理渲染流程,其中某一个 promise 会在 iframe 加载完成后给出结果,同时, epubjs 还会在触发 resize 时会销毁原有 iframe 重新渲染
如果 iframe 在没有加载好之前被销毁了,则 promise 状态永远为 pending,队列阻塞,导致所有操作都卡死
epubjs 在 resize 销毁重渲染时会错误的计算当前位置,具体表现为本来我在第三页,缩放后回到了开头,此时翻页也会失效,原因未知( //TODO: 有空再看看)
解决
第一点是最容易触发的,我已向 epubjs 提了一个 PR 来修复该问题
第二点触发原因未知,触发几率也很小,有空再看看
未完待续